

Hola a todos, mi nombre es Daniel Monzón y en este primer post me gustaría comentar un tema que he investigado hace poco y que me parece muy interesante. Vamos a hablar sobre Unicode, qué es y cómo usarlo en ejercicios de Red Team o pentests.
Unicode (al contrario de lo que parece) no es un tipo de encoding, es una base de datos que mapea cualquier símbolo (glifo) existente a un número único llamado code point (al cual se le asigna también un nombre único).
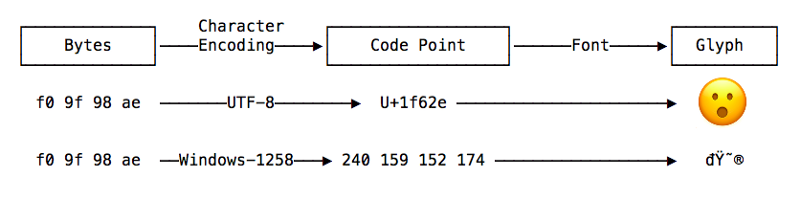
Por ejemplo “A” se mapea a U+0041 y “a” se mapea a U+0061
Existen caracteres Unicode desde U+000000 hasta U+10FFFF (hay más de un millón de símbolos). Unicode divide todos esos posibles símbolos en “planos”, el más conocido es el BMP (Basic Multilingual Plane) que va desde U+0000 hasta U+FFFF (es el plano de Unicode número 1, existen 16 más, denominados “planos astrales”).
Unicode se puede usar en Javascript y la manera de representarlo es con secuencias de escape:
https://mathiasbynens.be/notes/javascript-escapes
Secuencias de escape Unicode (para BMP):
\u0041\u0042
Secuencias de escape Unicode ECMA Script 6:
\u{41} (BMP)
\u{1F4A9} (Planos “astrales”) (A partir de PHP 7 también se puede usar esto en PHP)

Los caracteres Unicode de los llamados planos “astrales” también se pueden representar como “surrogate pairs” en UTF-16 (ver https://en.wikipedia.org/wiki/UTF-16)
Existe otra feature de Unicode llamada normalización. Existe de varios tipos: NFC, NFD, NFKD, NFKC. La idea es “normalizar” algunos code-points para acabar teniendo el mismo carácter.
Podemos hacer pruebas en Python con el módulo «unicodedata» y su función normalice, también hay funciones implementadas para esto en PHP (https://www.php.net/manual/en/class.normalizer.php)
Ver: https://en.wikipedia.org/wiki/Unicode_equivalence

Ahora bien, ¿qué podemos hacer nosotros como atacantes con Unicode?
- Podemos usar https://github.com/UndeadSec/EvilURL para buscar nombres de dominios parecidos a los que queremos suplantar para hacer phishing (como veis la URL que genera no existe)

2) Inyecciones SQL:
– Se puede usar Unicode para bypassear funciones de sanitización de input custom (aprovechando la normalización de caracteres Unicode).
https://medium.com/hackernoon/ʼ-śℇℒℇℂʈ-how-unicode-homoglyphs-will-break-your-custom-sql-injection-sanitizing-functions-1224377f7b51
https://medium.com/bugbountywriteup/moodle-lms-sql-injection-using-unicode-characters-fe01232f2727
-También podemos usar Unicode para terminar strings en MySQL (en vez de — – por ejemplo) si el charset no es utf8mb4

3) WAF bypass (ver PayloadAllTheThings XSS en Github)
https://medium.com/bugbountywriteup/unicode-vs-waf-xss-waf-bypass-128cd9972a30
https://jlajara.gitlab.io/web/2020/02/19/Bypass_WAF_Unicode.html
4) Path traversal: también podemos usarlo para conseguir path traversals que tengan restricciones de caracteres (usando %c1%1c y %c0%af por ejemplo en vez de ../)
https://www.securityfocus.com/archive/1/473311/100/0/threaded
%c0%ae%c0%ae (representación hexadecimal de ..) y otros payloads de PayloadAllTheThings
5) Extensiones de archivos: se pueden “falsificar” extensiones de archivos con RTLO (U+202E), además de bypassear whitelists y blacklists tradicionales con extensiones equivalentes en Unicode.
https://github.com/ctrlaltdev/RTLO-attack (con esto podemos ver cómo aparentemente se “cambia” la extensión del archivo)

https://medium.com/swlh/hacking-the-web-with-unicode-73d0f0c97aab
6) CRLF y Open redirects:
\u2028 y \u2029 -> se les pueden dar el mismo uso que a %0a y %0d
Payload CRLF Unicode -> %E5%98%8A%E5%98%8DSet-Cookie:%20test
https://medium.com/cyberverse/crlf-injection-playbook-472c67f1cb46
https://dl.packetstormsecurity.net/1602-exploits/Node-js-Response-Splitting.pdf
https://pentester.land/cheatsheets/2018/11/02/open-redirect-cheatsheet.html
7) Account takeover: si sabemos que existe un usuario admin en una app web, hay veces que al registrar un usuario como ÃđᛖᎥnpodemos acabar sobreescribiendo sus datos y tomando el control de su cuenta. O incluso si solo permiten registro desde cierto dominio podemos bypassear la whitelist con Unicode. A veces incluso también podemos abusar de esto en password resets.
https://engineering.atspotify.com/2013/06/18/creative-usernames/
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-19844
https://www.bugcrowd.com/blog/hacking-unicode-like-a-boss/
Para encontrar caracteres equivalentes en Unicode yo suelo usar: http://www.irongeek.com/homoglyph-attack-generator.php
8) Errores de memoria: muchos programas tienen problemas para manejar caracteres Unicode y da lugar a errores tipo stack buffer overflow, heap-based overflow, out-of-bounds read/write, integer overflow, UAF y otros por el estilo.
En Unicode existen desde los típicos caracteres de control: https://www.compart.com/en/unicode/category/Cc hasta caracteres vacíos (U+2800 y U+200C), un ejemplo de esto pueden ser los títulos de algunos vídeos como este: https://www.youtube.com/watch?v=dmBvw8uPbrA
Incluso hay “colisiones” en Unicode al convertir de mayúsculas a minúsculas que pueden acabar siendo fallos de seguridad: https://eng.getwisdom.io/hacking-github-with-unicode-dotless-i/
Hay un sinfín de cosas curiosas y útiles que pueden hacerse con Unicode, seguramente muchas más de las que yo he podido encontrar. Espero que os haya gustado. ¡Hasta la próxima!
-Daniel Monzón-
Referencias:
https://eng.getwisdom.io/awesome-unicode
http://www.russellcottrell.com/greek/utilities/SurrogatePairCalculator.htm
https://www.youtube.com/watch?v=HhIEDWmQS3w
https://book.hacktricks.xyz/pentesting-web/unicode-normalization-vulnerability
https://medium.com/concerning-pharo/an-implementation-of-unicode-normalization-7c6719068f43
http://www.unicode.org/reports/tr15/
https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/
https://withblue.ink/2019/03/11/why-you-need-to-normalize-unicode-strings.html
https://exploringjs.com/es6/ch_unicode.html
https://github.com/walling/unorm
https://www.bugcrowd.com/blog/hacking-unicode-like-a-boss/
http://www.irongeek.com/homoglyph-attack-generator.php
https://medium.com/swlh/hacking-the-web-with-unicode-73d0f0c97aab
https://0xsha.io/posts/the-fall-of-mighty-django-exploiting-unicode-case-transformations
https://www.hackplayers.com/2018/04/evilurl-dominios-para-ataques-homograficos.html
https://www.online-toolz.com/tools/text-unicode-entities-convertor.php

